Quantum “Atoms” of Data
 This article explains how to create quantum “atoms” of data to avoid a paradox of uncertainty on systems that have distributed transactions or human data entry.
This article explains how to create quantum “atoms” of data to avoid a paradox of uncertainty on systems that have distributed transactions or human data entry.
Banks Do It All The Time
If you go to your online banking application, you’ll notice that a number of recent transactions are in a “pending” state. Since the global banking system is distributed in a way where there is no unified order in which events happen, transactional order can be interpreted in different ways. Banks tend to use selective interpretation to give the customer the benefit of the doubt or to charge extra penalties, depending on the nature of the account and how they want to treat their customers.
It Applies To All Time Series Data
Unless your system gives a unique identifier or timestamp to all data with perfect accuracy, the uncertainty will exist in your data. Most of it is from human data entry. Unless they synchronize their watches down the microsecond and enter data with that level of accuracy, there will be some uncertainty in terms of what order things happened in. To solve this, we will create an “Atom” of time-series data at a specified level of granularity. For most applications, daily granularity is sufficient.
Creating Atoms of Data To Remove Quantum Uncertainty
Quantum physics teaches us that the nature of subatomic particles in inherently uncertain. Our world stops being as real as we’d like and we can no longer observe with absolute precision. We actually run into he same issues in our data model when multiple events supposedly occur at the same time. When we have credits and debits that claim to be happening in the same microsecond, our aggregation becomes ambiguous.
There is no correct order to put the transactions in and all permutations of order are equally valid. Sometimes we get lucky and the order in which the data was entered works itself out but there are always exceptions to the rule.
If you take a look at your online banking app, they deal with this by putting transactions in a “pending” state until the end of the day. They also do this to maximize or minimize the interest charged depending on their objective. You probably have a friend who has paid extra penalties when they thought they put their deposit in on time.
Rather than play this game, lets remove the uncertainty by atomizing our data. How do we do this? We will pick the smallest possible element in our date dimension and have our data model reflect the net changes for that period. For most systems, daily granularity is sufficient so let’s pick that. Essentially, we are saying combining all invoices and payments for each day into a single record that we will use for deeper analysis. The resulting view gives us one record per customer for every date that has either an invoice or payment. Every record in this view is an “atom” of data that can not be reduced anymore without inviting ambiguity.
Making It Work With Northwind
Let’s this example is easy to work with, let’s the Orders Table from the Northwind sample database to create a view that simulates a dataset with credit and debit transactions. You could create a similar view on nearly any database. This query will use the OrderDate to simulate invoices.
[sql]SELECT
CustomerID AS Customer,
OrderDate AS TransactionDate,
Freight AS Invoiced,
0 AS Paid
FROM ORDERS[/sql]
Next, let’s create a view called Transactions to simulate the data we need form Northwind. You could create as similar view in your system.
[sql]CREATE VIEW Transactions AS
SELECT 'Invoice' AS TransactionType,
CustomerID AS Customer, OrderDate AS TransactionDate,
Freight AS Amount
FROM Orders
UNION
SELECT 'Payment' AS TransactionType,
CustomerID AS Customer,
ShippedDate AS TransactionDate,
-Freight AS Amount
FROM Orders where ShippedDate IS NOT NULL[/sql]
This gives us a nice, clean view to work with.
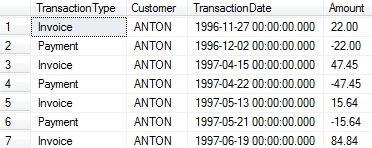
Conclusion
Now we simply do a SUM of the amount and GROUP BY the Date to compress all the data for each date into a single “atom” of data for each customer.
[sql]SELECT Customer, TransactionDate,SUM(Amount) AS Net FROM Transactions GROUP BY Customer, TransactionDate Each Date now has a single Net amount of change that you can work with. [/sql]
Creating an “atomic” view would result in a high performance data source that guarantees consistency and eliminates a paradox of uncertainty around how to interpret the order of transactions in a given day.
We now have a view that we can plug into a rich reporting experience like Izenda. Try it today to see if the added flexibility of this approach will benefit your user community.